8 Joining road crash tables
8.1 STATS19 tables
Thus far, we have been working primarily with ‘accident’ level data, but there is much useful data in other tables.
As outlined in the stats19 vignette — which you can view by entering the command vignette("stats19") to get extended help pages about R packages — there are three main tables that contain STATS19 data.
Let’s read-in data from 2019 to take a look:
library(stats19)
ac = get_stats19(year = 2019, type = "accidents")
ca = get_stats19(year = 2019, type = "casualties")
ve = get_stats19(year = 2019, type = "vehicles")The three objects read-in above correspond to the main types of entity that are recorded by the police:
- Crashes: The ‘crash event’ table contains general data about crashes, including where and when they happened and the conditions in which the crash occurred (e.g. light levels in the column
light_conditionsin theacobject). For historical reasons, crash level data is stored in tables called ‘Accidents’ (a term that has fallen out of favour because it implies that nobody was at fault). See names for all 33 variables in the crashes table by running the commandnames(ac). Crashes range from collisions involving only one vehicle and another entity (e.g. a person on foot, bicycle or a car) causing only ‘slight’ injuries such as a graze, to multi-vehicle pile-ups involving multiple deaths and dozens of slight and serious injuries. - Casualties: The casualties table, assigned to an object called
cain the code above, contains data at the casualty level. As you will see by running the commandnames(ca), the STATS19 casualties table has 16 variables includingage_of_casualty,casualty_severityandcasualty_type, reporting the mode of transport in which the person was travelling when they were hit. - Vehicles: The vehicles table, assigned to
veabove, contains information about the vehicles and their drivers involved in each collision. As you will see by running the commandnames(ve), the 23 variables in this table includesvehicle_type,hit_object_off_carriagewayandfirst_point_of_impact. Information about the driver of vehicles involved is contained in variables such asage_of_driver,engine_capacity_ccandage_of_vehicle.
Each table represents the same phenomena: road casualties in Great Britain in 2019. Therefore, you may expect they would have the same number of rows, but this is not the case:
## [1] 117536## [1] 153158## [1] 216381The reason for this is that there are, on average, more than one casualty per crash (e.g. when a car hits two people), and more than one vehicle, including bicycles, per crash18 We can find the average number of casualties and vehicles per crash as follows:
## [1] 1.303073## [1] 1.840976The output of the commands above show that there are around 1.3 casualties and 1.8 vehicles involved in each crash record in the STATS19 dataset for 2019.
Each table contains a different number of columns, reporting the characteristics of each casualty and each driver/vehicle for the ca and ve datasets respectively.
## [1] 33## [1] 16## [1] 23The output of the previous code chunk shows that we have more variables in the ‘accidents’ table than the others but the others, but the other tables are data rich with 16 columns on the casualties and 23 on the vehicles. To check that the datasets are consistent, we can check that the number of casualties reported in the crashes table is equal to the number of rows in the casualties table, and the same for the vehicles table:
## [1] TRUE## [1] TRUE8.2 Joining casualty data
To join casualty (or vehicle) data onto the ac object above, the inner_join() function from dplyr can be used as follows:
## Joining, by = "accident_index"The above command worked because the two datasets have a shared variable name: accident_index.
Note that the command worked by duplicating accident records for multiple casualties.
We can see this finding the accident that had the most crashes and printing the results in the ac and new joined dataset, as follows:
id_with_most_crashes = ac %>%
top_n(n = 1, wt = number_of_casualties) %>%
pull(accident_index)
id_with_most_crashes## [1] "2019500885809"ac %>% filter(accident_index == id_with_most_crashes) %>%
select(accident_index, accident_severity, number_of_vehicles, number_of_casualties)## # A tibble: 1 x 4
## accident_index accident_severity number_of_vehicles number_of_casualties
## <chr> <chr> <int> <int>
## 1 2019500885809 Serious 1 52ac_cas_joined %>% filter(accident_index == id_with_most_crashes) %>%
select(accident_index, accident_severity, number_of_vehicles, number_of_casualties, casualty_reference)## # A tibble: 52 x 5
## accident_index accident_severi… number_of_vehic… number_of_casua…
## <chr> <chr> <int> <int>
## 1 2019500885809 Serious 1 52
## 2 2019500885809 Serious 1 52
## 3 2019500885809 Serious 1 52
## 4 2019500885809 Serious 1 52
## 5 2019500885809 Serious 1 52
## 6 2019500885809 Serious 1 52
## 7 2019500885809 Serious 1 52
## 8 2019500885809 Serious 1 52
## 9 2019500885809 Serious 1 52
## 10 2019500885809 Serious 1 52
## # … with 42 more rows, and 1 more variable: casualty_reference <int>8.3 Joining vehicle data
The same approach can be used to join vehicle data onto the crash record data:
## Joining, by = "accident_index"This information can be used as the basis of who-hit-who visualisation, in this case looking at vehicles involved in the most common type of casualties (recoded using the trafficalmr package):
remotes::install_github("saferactive/trafficalmr")
library(trafficalmr)
ac_cas_joined$cas_type = tc_recode_casualties(ac_cas_joined$casualty_type)
p = c(`HGV_occupant|Minibus_occupant|Taxi_occupant|Moto*.+` = "Other")
ac_cas_joined$cas_type = tc_recode_casualties(ac_cas_joined$cas_type, pattern = p)
barplot(table(ac_cas_joined$cas_type))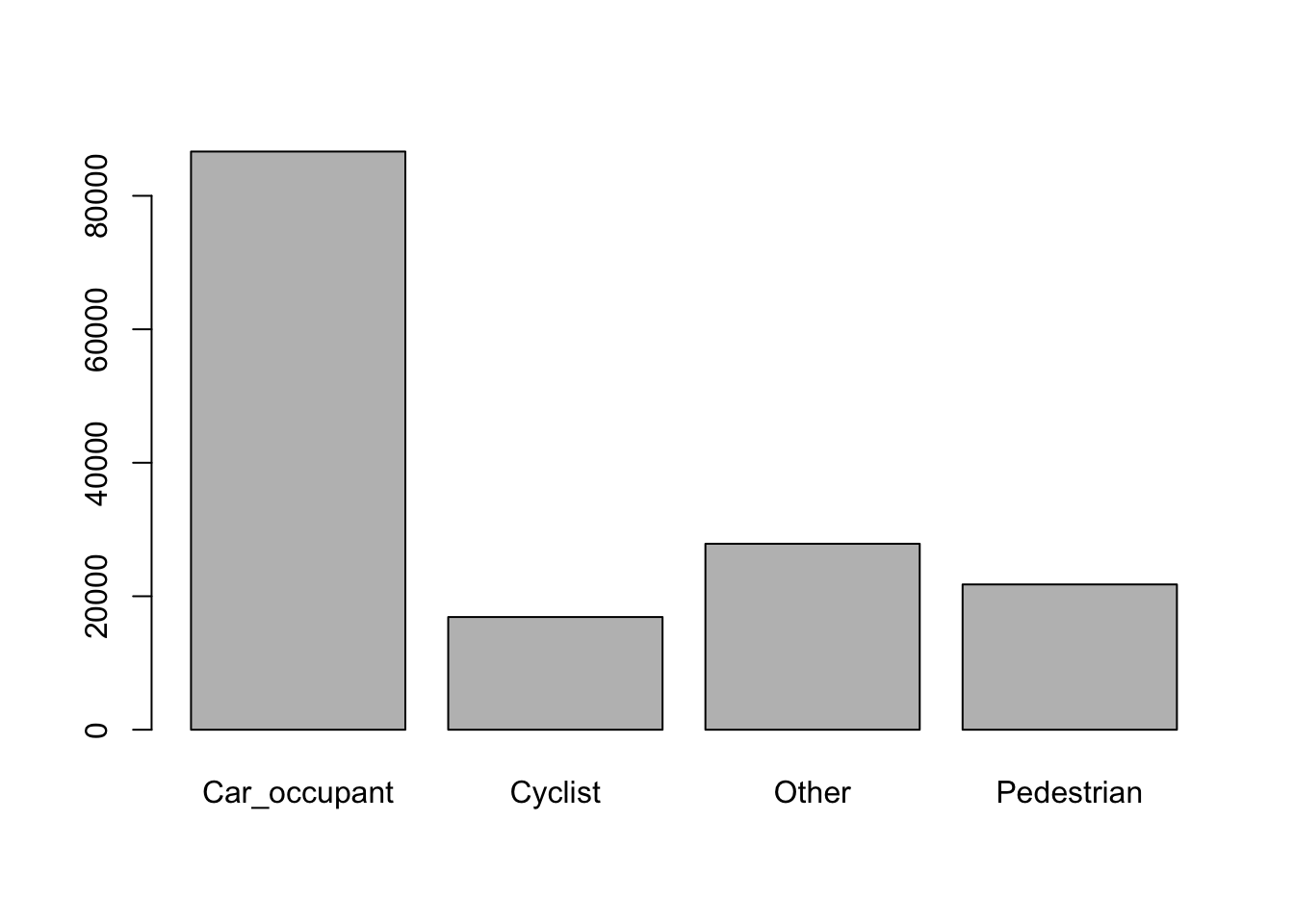
Figure 8.1: Barplot of recoded casualty type frequencies
To find the largest vehicle involved in each casualty, we can similarly pre-process the vehicle data as follows:
p = c(`Van*.+` = "Van", `Pedal cycle` = "Bicycle",
`(M|m)otorcycle*.+|Elec*.+` = "Motorcycle",
`Taxi*|Data*.+|Agri*.+|Ridden*.+|Mobility*.+|Tram*.+|(M|m)otorcycle*.+|Elec*.+` = "Other",
`Bus*.+` = "Bus", `Bus|Minibus*.+|Other*.+` = "Other", `Goods*.+` = "HGV")
ac_veh_joined$veh_type = tc_recode_vehicle_type(ac_veh_joined$vehicle_type, p)
# dput(unique(ac_veh_joined$veh_type))
l = c("Bicycle", "Car", "Other", "Van", "HGV")
ac_veh_joined$vehicle = factor(ac_veh_joined$veh_type, levels = l, ordered = TRUE)
summary(ac_veh_joined$vehicle)## Bicycle Car Other Van HGV
## 17437 152686 28450 12579 5229ac_veh_largest = ac_veh_joined %>%
group_by(accident_index) %>%
summarise(largest_vehicle = max(vehicle))## Joining, by = "accident_index"cas_veh_table = table(ac_cas_veh_largest$cas_type, ac_cas_veh_largest$largest_vehicle)
cvt_df = as.data.frame(cas_veh_table)
ggplot(cvt_df) +
geom_bar(aes(Var2, Freq, fill = Var1), stat = "identity") +
scale_fill_discrete("Casualty type") +
xlab("Largest vehicle involved") +
ylab("Number of casualties")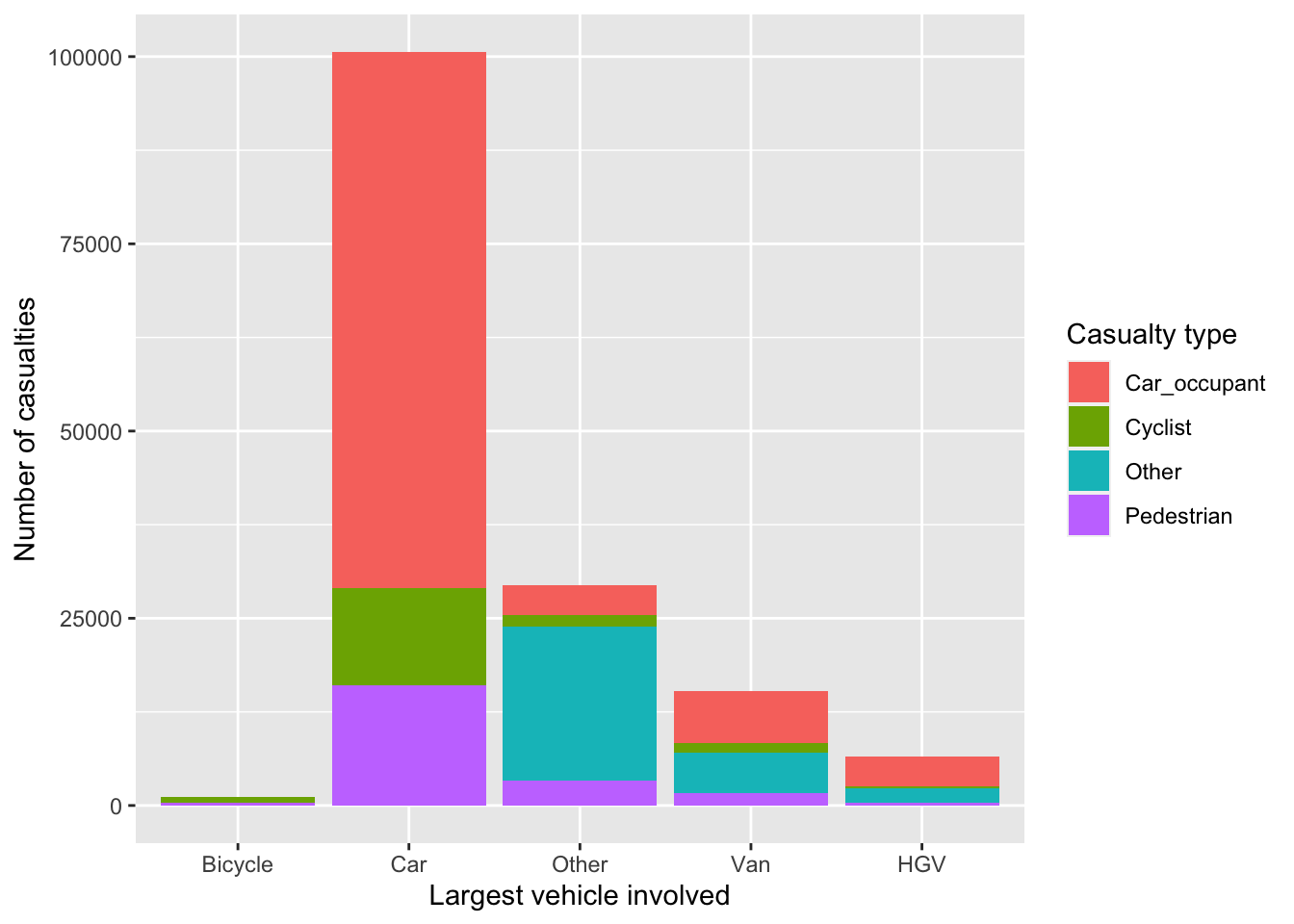
Figure 8.2: ‘Who hit who’ visualisation of number of casualties (y axis) hurt in crashes involving different vehicle types (largest vehicle in each crash on Y axis).
8.4 Case study: London
The three main tables we have just read-in can be joined by the accident_index variable and then filtered using other variables. This is demonstrated in the code chunk below, which subsets all casualties that took place in London, and counts the number of casualties by severity for each crash:
library(tidyr)
library(dplyr)
ac_sf = format_sf(ac)
# table(ac_sf$police_force)
lnd_police = c("City of London", "Metropolitan Police")
ac_lnd = ac_sf %>%
filter(police_force %in% lnd_police)
ca_lnd = ca %>%
filter(accident_index %in% ac_lnd$accident_index)
cas_types = ca_lnd %>%
select(accident_index, casualty_type) %>%
group_by(accident_index) %>%
summarise(
Total = n(),
walking = sum(casualty_type == "Pedestrian"),
cycling = sum(casualty_type == "Cyclist"),
passenger = sum(casualty_type == "Car occupant")
)
cj = left_join(ac_lnd, cas_types)What just happened? We found the subset of casualties that took place in London with reference to the accident_index variable.
Then we used the dplyr function, summarise(), to find the number of people who were in a car, cycling, and walking when they were injured.
This new casualty dataset is joined onto the crashes_lnd dataset.
The result is a spatial (sf) data frame of ac in London, with columns counting how many road users of different types were hurt.
The joined data has additional variables:
## [1] "Total" "walking" "cycling" "passenger"As a simple spatial plot, we can map all crashes that occurred in London in 2017, with the colour related to the total number of people hurt in each crash. Placing this plot next to a map of London provides context:
plot(
cj[cj$cycling > 0, "speed_limit", ],
cex = cj$Total[cj$cycling > 0] / 3,
main = "Speed limit (cycling)"
)
plot(
cj[cj$passenger > 0, "speed_limit", ],
cex = cj$Total[cj$passenger > 0] / 3,
main = "Speed limit (passenger)"
)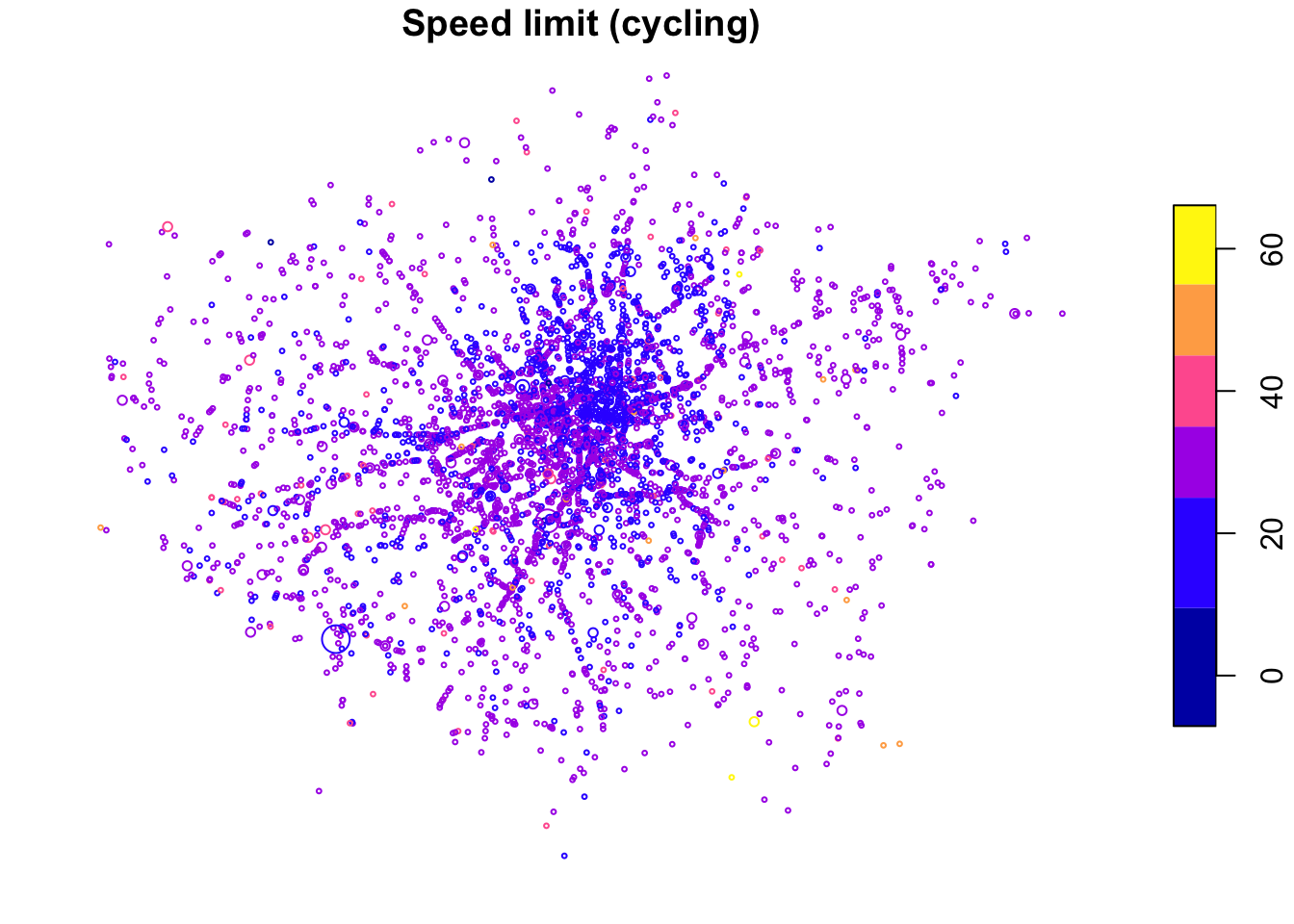
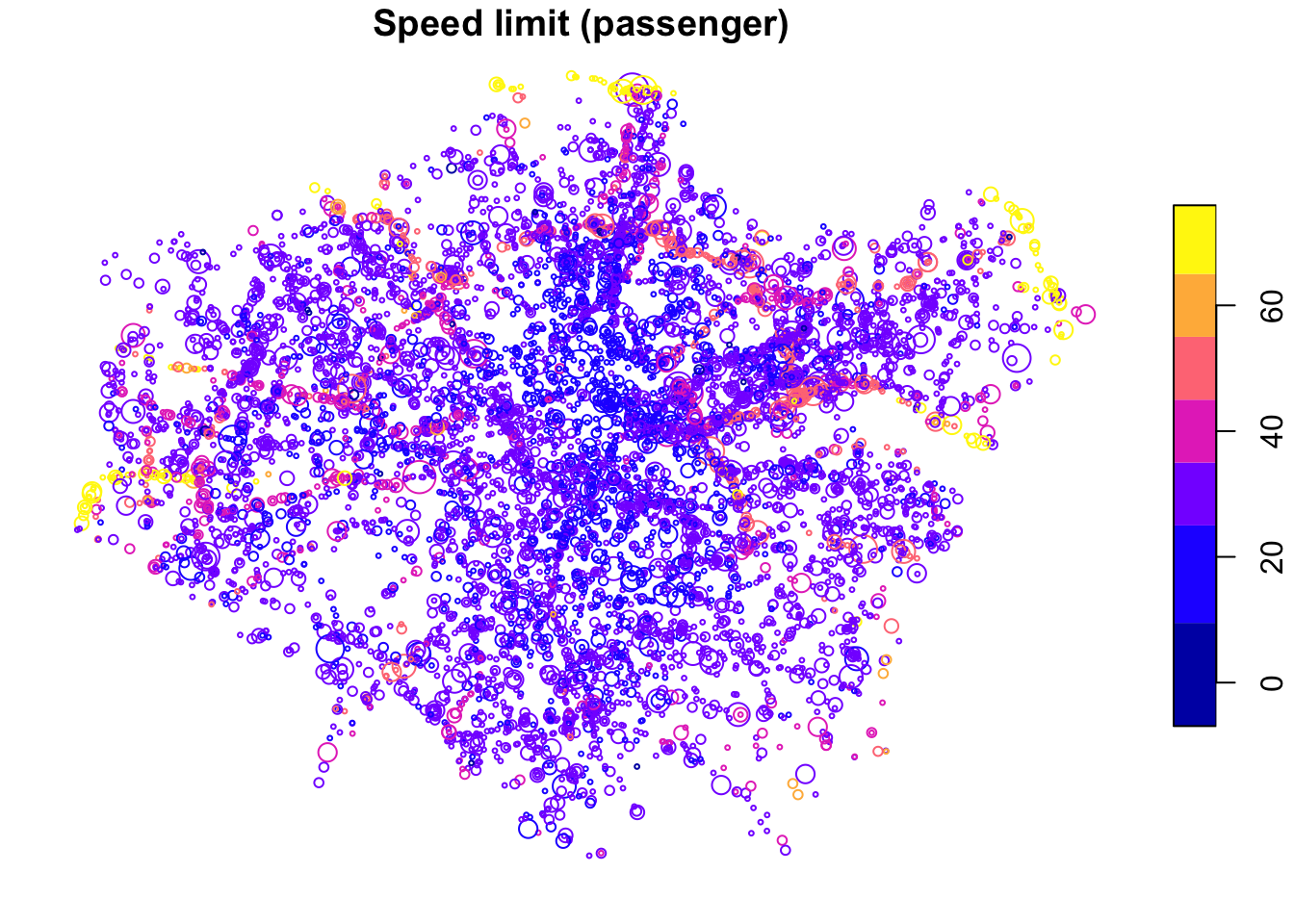
The spatial distribution of crashes in London clearly relates to the region’s geography. Car crashes tend to happen on fast roads, including busy dual carriageway roads, displayed in yellow in Figure 8.2 above. Cycling is as an urban activity, and the most bike crashes can be found in or near the centre of London, which has a comparatively high level of cycling (compared to the low baseline of 3%). This can be seen by comparing the previous map (Figure 8.1) with an overview of the area, from an academic paper on the social, spatial and temporal distribution of bike crashes (Lovelace, Roberts, and Kellar 2016).
In addition to the Total number of people hurt/killed, cj contains a column for each type of casualty (cyclist, car occupant, etc.), and a number corresponding to casualties in crashes involving each type of vehicle.
It also contains the geometry column from ac_sf.
In other words, joins allow the casualties and vehicles tables to be geo-referenced.
We can then explore the spatial distribution of different casualty types.
For example, Figure 8.3 shows the spatial distribution of pedestrians and car passengers hurt in car crashes across London in 2017, via the following code:
library(ggplot2)
ac_types = cj %>%
filter(accident_severity != "Slight") %>%
mutate(type = case_when(
walking > 0 ~ "Walking",
cycling > 0 ~ "Cycling",
passenger > 0 ~ "Passenger",
TRUE ~ "Other"
))
ggplot(ac_types, aes(size = Total, colour = speed_limit)) +
geom_sf(show.legend = "point", alpha = 0.3) +
facet_grid(vars(type), vars(accident_severity)) +
scale_size(
breaks = c(1:3, 12),
labels = c(1:2, "3+", 12)
) +
scale_color_gradientn(colours = c("blue", "yellow", "red")) +
theme(axis.text = element_blank(), axis.ticks = element_blank())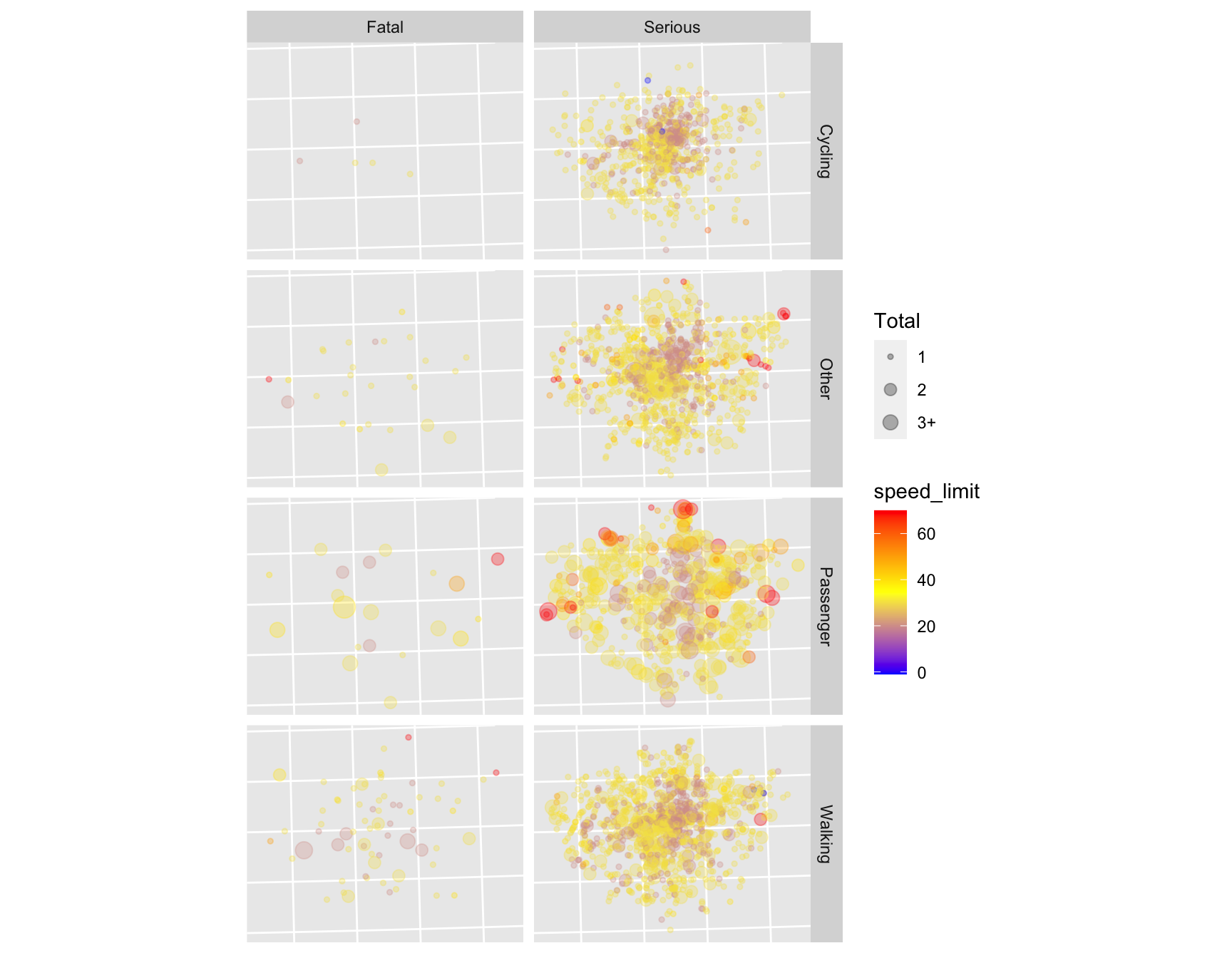
Figure 8.3: Spatial distribution of serious and fatal crashes in London, for cycling, walking, being a car passenger and other modes of travel. Colour is related to the speed limit where the crash happened (red is faster) and size is proportional to the total number of people hurt in each crash (legend not shown).
Exercises:
- There is a lot going on in the code in this chapter, the most advanced of the guide. With reference to online help, work through the code line-by-line and look-up any aspects of the code that you do not fully understand to help figure out what is going on.
- Reproduce the final figures for a different city of your choice (not London).
- Bonus: Create more attractive interactive maps to show the spatial distribution of different casualty types in the city of your choice.
STATS19 data contains information on when a single vehicle crashes without involvement of any other vehicles, but not when a lone cyclist crashes without any other vehicle involved.↩︎